释放双眼,带上耳机,听听看~!
告警日志为如下:
Ceph Object Storage Daemon takes too much time to resize.ceph集群监控异常
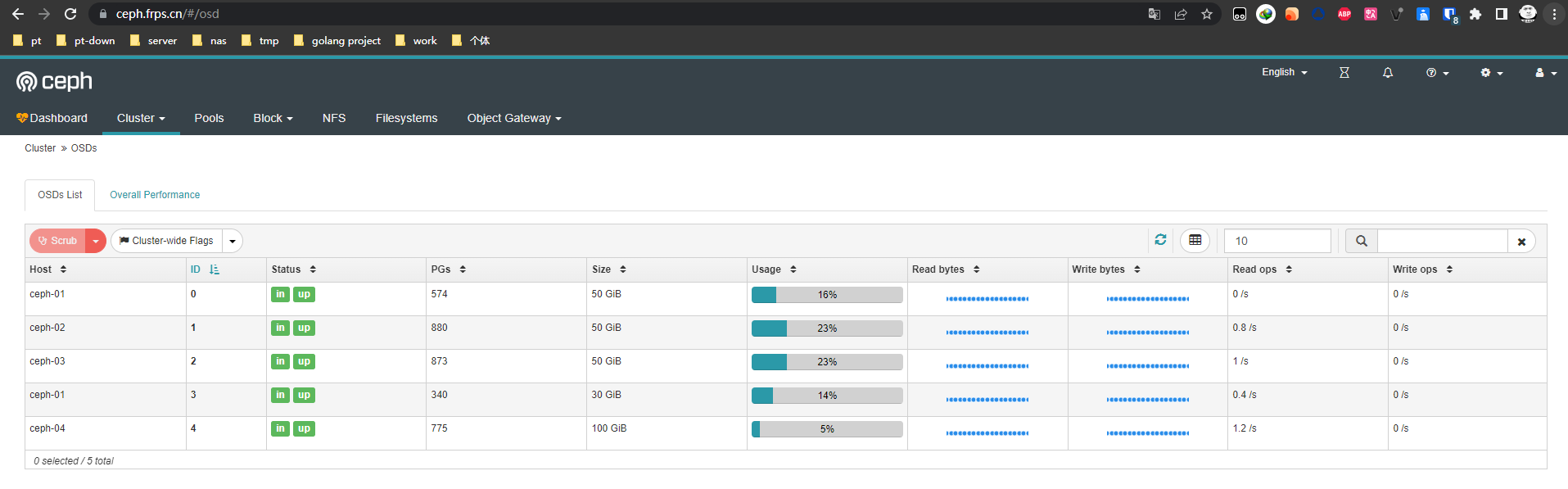
使用ceph osd命令查看osd状态
[root@ceph-01 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.27338 root default
-3 0.07809 host ceph-01
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000
-5 0.04880 host ceph-02
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host ceph-03
2 hdd 0.04880 osd.2 up 1.00000 1.00000
-9 0.09769 host ceph-04
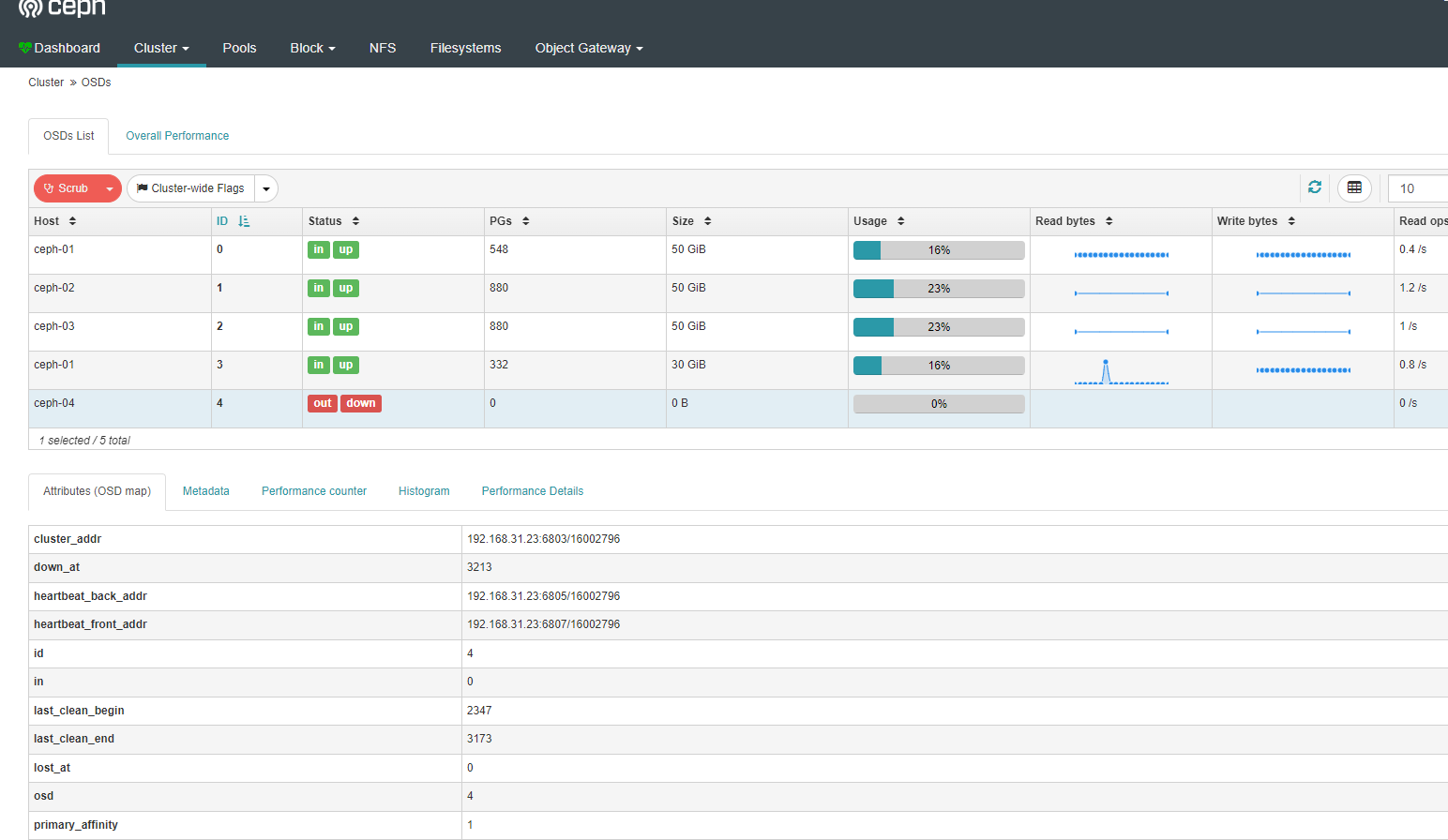
4 hdd 0.09769 osd.4 down 0 1.00000 通过osd tree我这边看到osd.4节点已经down掉
接下来移除osd.4,在重新加入
ceph-deploy管理节点操作
[root@ceph-01 ~]# ceph osd out osd.4 #将down的osd踢出ceph集群
osd.4 is already out.
[root@ceph-01 ~]# ceph osd rm osd.4 #将down的osd删除
removed osd.4
[root@ceph-01 ~]# ceph osd crush rm osd.4 #将down的osd从CRUSH中删除
removed item id 4 name 'osd.4' from crush map
[root@ceph-01 ~]# ceph auth del osd.4 #删除osd的认证信息
entity osd.4 does not existceph-04节点 (osd down)节点操作
查看异常磁盘,之前添加的是100G节点异常,我这边直接看osd 100g的硬盘位置
[root@ceph-04 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 49G 0 part
├─centos-root 253:0 0 45.1G 0 lvm /
└─centos-swap 253:1 0 3.9G 0 lvm [SWAP]
sdb 8:16 0 50G 0 disk
└─ceph--25ea7f02--00de--4bbe--a757--d1a32404d81e-osd--block--da8d4de9--c2d0--44c5--8e5f--607c5fef0d1e 253:3 0 50G 0 lvm
sdc 8:32 0 100G 0 disk
└─ceph--40ba9b1c--eb45--4185--9eae--085468350ed5-osd--block--ee4dc429--e4b0--4265--9e1d--2f1a12de12d6 253:2 0 100G 0 lvm
sr0 11:0 1 1024M 0 rom 找到名称为ceph--40ba9b1c--eb45--4185--9eae--085468350ed5-osd--block--ee4dc429--e4b0--4265--9e1d--2f1a12de12d6,磁盘路径为/dev/sdc
到ceph-04节点,查看lvm信息,进行删除lvm,格式化操作
[root@ceph-04 ~]# dmsetup status #查看lvm信息
ceph--25ea7f02--00de--4bbe--a757--d1a32404d81e-osd--block--da8d4de9--c2d0--44c5--8e5f--607c5fef0d1e: 0 104849408 linear
ceph--40ba9b1c--eb45--4185--9eae--085468350ed5-osd--block--ee4dc429--e4b0--4265--9e1d--2f1a12de12d6: 0 209707008 linear
centos-swap: 0 8126464 linear
centos-root: 0 94617600 linear
[root@ceph-04 ~]# dmsetup remove ceph--40ba9b1c--eb45--4185--9eae--085468350ed5-osd--block--ee4dc429--e4b0--4265--9e1d--2f1a12de12d6 #对比lsblk命令,找到对应的/dev/sdc对应的名称,进行删除操作
[root@ceph-04 ~]# mkfs.ext4 /dev/sdc #格式化/dev/sdc
mke2fs 1.42.9 (28-Dec-2013)
/dev/sdc is entire device, not just one partition!
Proceed anyway? (y,n) y #输入yes
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
6553600 inodes, 26214400 blocks
1310720 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=2174746624
800 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information:
done上面我们的ceph-04节点硬盘已经初始化了
接下来到ceph-01节点进行重新添加osd.4节点
[root@ceph-01 ~]# cd ceph-deploy #需要进入到ceph-deploy目录中开始添加节点
[root@ceph-01 ceph-deploy]# ceph-deploy osd create ceph-04 --data /dev/sdc #指定data为原来的盘
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy osd create ceph-04 --data /dev/sdc
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] bluestore : None
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x2349680>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] fs_type : xfs
[ceph_deploy.cli][INFO ] block_wal : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] journal : None
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] host : ceph-04
[ceph_deploy.cli][INFO ] filestore : None
[ceph_deploy.cli][INFO ] func : <function osd at 0x2335758>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] zap_disk : False
[ceph_deploy.cli][INFO ] data : /dev/sdc
[ceph_deploy.cli][INFO ] block_db : None
[ceph_deploy.cli][INFO ] dmcrypt : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] dmcrypt_key_dir : /etc/ceph/dmcrypt-keys
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.osd][DEBUG ] Creating OSD on cluster ceph with data device /dev/sdc
root@ceph-04's password:
root@ceph-04's password:
[ceph-04][DEBUG ] connected to host: ceph-04
[ceph-04][DEBUG ] detect platform information from remote host
[ceph-04][DEBUG ] detect machine type
[ceph-04][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.4.1708 Core
[ceph_deploy.osd][DEBUG ] Deploying osd to ceph-04
[ceph-04][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph-04][DEBUG ] find the location of an executable
[ceph-04][INFO ] Running command: /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdc
[ceph-04][WARNIN] Running command: /bin/ceph-authtool --gen-print-key
[ceph-04][WARNIN] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new c5f65255-2ec8-4ec5-8ac2-c7934e983e3f
[ceph-04][WARNIN] Running command: /usr/sbin/vgcreate --force --yes ceph-eb320f84-9a7d-4821-98e2-dc35134e6f4c /dev/sdc
[ceph-04][WARNIN] stdout: Wiping ext4 signature on /dev/sdc.
[ceph-04][WARNIN] stdout: Physical volume "/dev/sdc" successfully created.
[ceph-04][WARNIN] stdout: Volume group "ceph-eb320f84-9a7d-4821-98e2-dc35134e6f4c" successfully created
查看osd tree状态
[root@ceph-01 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.27338 root default
-3 0.07809 host ceph-01
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000
-5 0.04880 host ceph-02
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host ceph-03
2 hdd 0.04880 osd.2 up 1.00000 1.00000
-9 0.09769 host ceph-04
4 hdd 0.09769 osd.4 up 1.00000 1.00000
查看ceph集群状态
[root@ceph-01 ceph-deploy]# ceph -s
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_WARN
Degraded data redundancy: 4431/9810 objects degraded (45.168%), 189 pgs degraded
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 78m)
mgr: ceph-03(active, since 42h), standbys: ceph-02, ceph-01
mds: cephfs-abcdocker:1 cephfs:1 i4tfs:1 {cephfs-abcdocker:0=ceph-02=up:active,cephfs:0=ceph-03=up:active,i4tfs:0=ceph-01=up:active}
osd: 5 osds: 5 up (since 62s), 5 in (since 62s); 245 remapped pgs
rgw: 2 daemons active (ceph-01, ceph-02)
task status:
data:
pools: 19 pools, 880 pgs
objects: 3.27k objects, 11 GiB
usage: 37 GiB used, 243 GiB / 280 GiB avail
pgs: 0.114% pgs not active
4431/9810 objects degraded (45.168%)
645/9810 objects misplaced (6.575%)
542 active+clean
140 active+remapped+backfill_wait
92 active+recovery_wait+undersized+degraded+remapped
91 active+recovery_wait+degraded
8 active+recovery_wait+remapped
4 active+recovery_wait+degraded+remapped
1 active+recovering+degraded
1 peering
1 active+recovering+undersized+degraded+remapped
io:
recovery: 8 B/s, 0 objects/s
progress:
Rebalancing after osd.4 marked in
[=================.............]
osd.4添加集群会进行数据同步,耐心等待数据同步完成即可
在ui界面中可以看到osd集群已经恢复