释放双眼,带上耳机,听听看~!
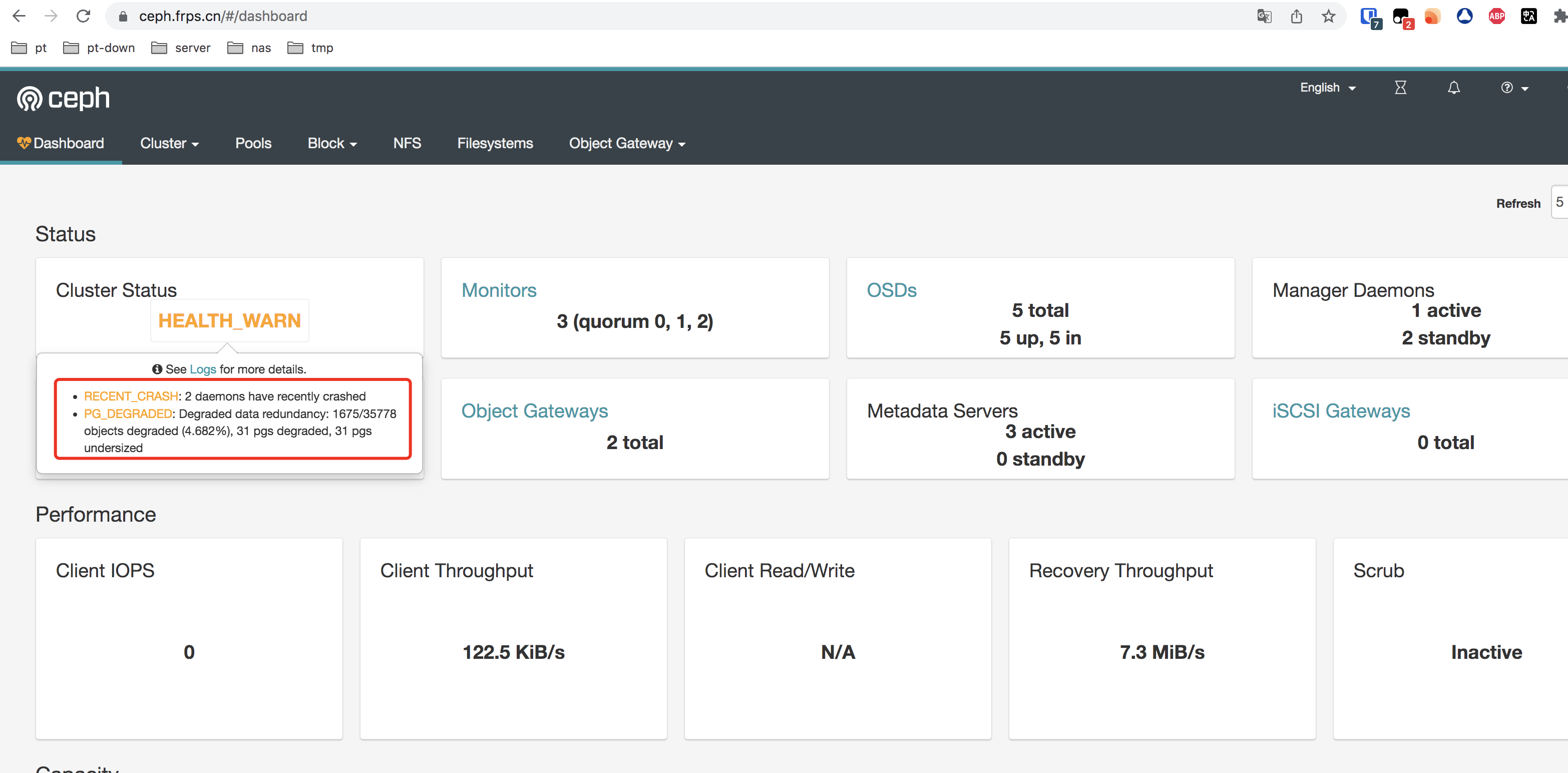
元旦早上收到ceph告警,mgr发送告警并没有提示告警内容是什么问题。只是提示我ceph健康为error。告警截图如下
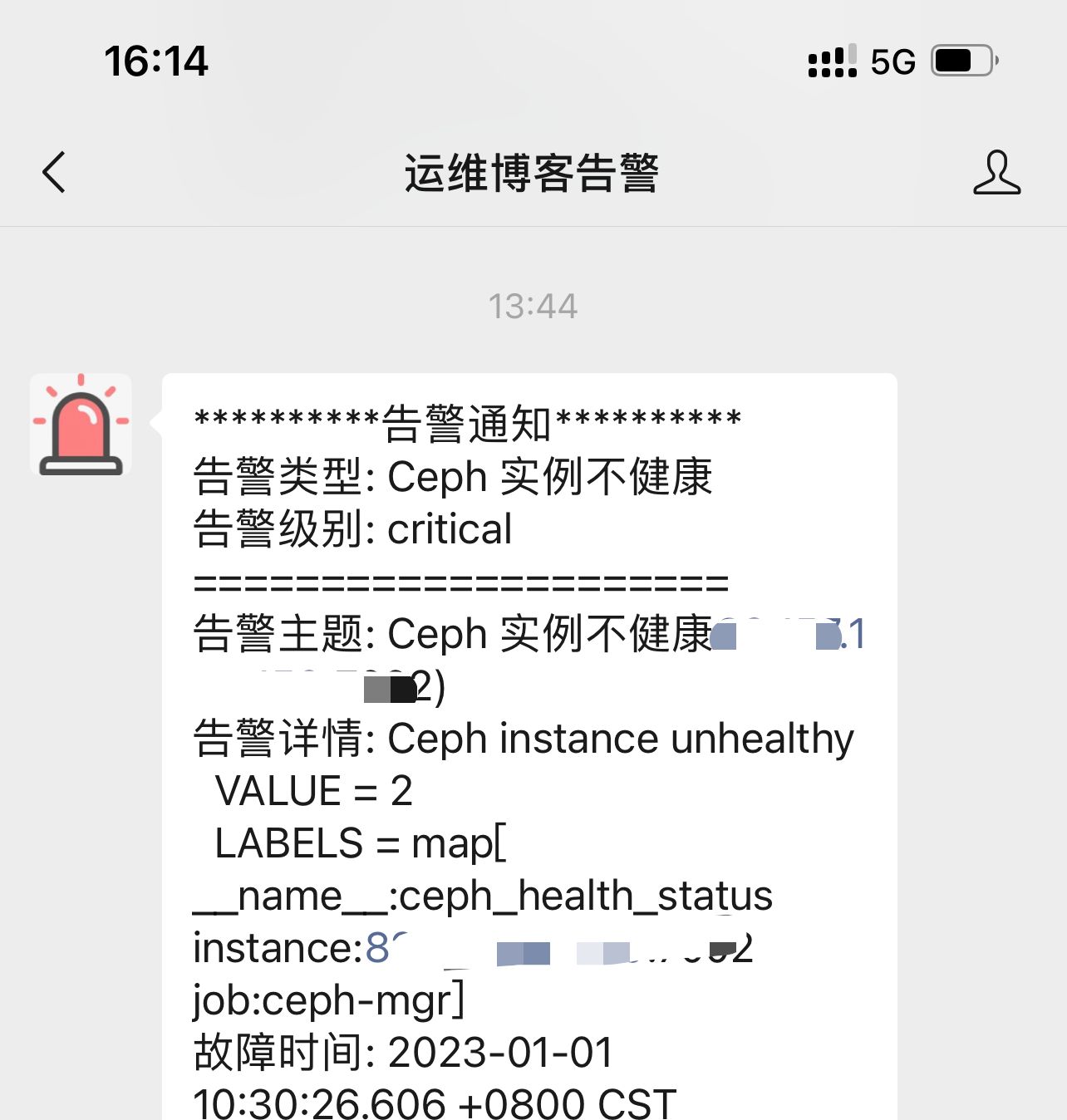
此时查看grafana告警也是异常的状态
接下来进入服务器排查问题
[root@ceph-01 ~]# ceph -s
cluster:
id: c8ae7537-8693-40df-8943-733f82049642
health: HEALTH_ERR
2 backfillfull osd(s)
19 pool(s) backfillfull
Degraded data redundancy: 21/37857 objects degraded (0.055%), 12 pgs degraded
Full OSDs blocking recovery: 12 pgs recovery_toofull
2 daemons have recently crashed
services:
mon: 3 daemons, quorum ceph-01,ceph-02,ceph-03 (age 11h)
mgr: ceph-03(active, since 2d), standbys: ceph-02, ceph-01
mds: cephfs-abcdocker:1 cephfs:1 i4tfs:1 {cephfs-abcdocker:0=ceph-02=up:active,cephfs:0=ceph-03=up:active,i4tfs:0=ceph-01=up:active}
osd: 4 osds: 4 up (since 2d), 4 in (since 5w)
rgw: 2 daemons active (ceph-01, ceph-02)
task status:
data:
pools: 19 pools, 880 pgs
objects: 12.62k objects, 47 GiB
usage: 143 GiB used, 37 GiB / 180 GiB avail
pgs: 21/37857 objects degraded (0.055%)
867 active+clean
12 active+recovery_toofull+degraded
1 active+clean+scrubbing+deep
io:
client: 4.0 MiB/s rd, 3.4 MiB/s wr, 218 op/s rd, 27 op/s wr通过ceph -s命令发现是服务器的osd硬盘不够,通过下面的命令看一下箱子的日志输出
[root@ceph-01 ~]# ceph health detail
HEALTH_ERR 2 full osd(s); 19 pool(s) full; Degraded data redundancy: 62/38073 objects degraded (0.163%), 34 pgs degraded; Full OSDs blocking recovery: 34 pgs recovery_toofull; 2 daemons have recently crashed
OSD_FULL 2 full osd(s)
osd.1 is full
osd.2 is full
POOL_FULL 19 pool(s) full
pool 'abcdocker' is full (no space)
pool '.rgw.root' is full (no space)
pool 'default.rgw.control' is full (no space)
pool 'default.rgw.meta' is full (no space)
pool 'default.rgw.log' is full (no space)
pool 'default.rgw.buckets.index' is full (no space)
pool 'default.rgw.buckets.data' is full (no space)
pool 'cephfs_data' is full (no space)
pool 'cephfs_metadata' is full (no space)
pool 'kubernetes' is full (no space)
pool 'fs_data' is full (no space)
pool 'fs_metadata' is full (no space)
pool 'kube' is full (no space)
pool 'abcdocker_rbd' is full (no space)
pool 'abcdocker_data' is full (no space)
pool 'cephfs-data' is full (no space)
pool 'cephfs-metadata' is full (no space)
pool 'i4t_data' is full (no space)
pool 'i4t_metadata' is full (no space)
PG_DEGRADED Degraded data redundancy: 62/38073 objects degraded (0.163%), 34 pgs degraded
pg 3.e is active+recovery_toofull+degraded, acting [2,0,1]
pg 11.4 is active+recovery_toofull+degraded, acting [1,3,2]
pg 11.5 is active+recovery_toofull+degraded, acting [1,3,2]
pg 11.8 is active+recovery_toofull+degraded, acting [3,2,1]
pg 11.a is active+recovery_toofull+degraded, acting [2,3,1]
pg 11.b is active+recovery_toofull+degraded, acting [3,1,2]
pg 11.d is active+recovery_toofull+degraded, acting [3,1,2]
pg 11.f is active+recovery_toofull+degraded, acting [1,2,3]
pg 11.1b is active+recovery_toofull+degraded, acting [1,2,3]
pg 11.21 is active+recovery_toofull+degraded, acting [2,3,1]
pg 11.27 is active+recovery_toofull+degraded, acting [2,1,3]
pg 11.33 is active+recovery_toofull+degraded, acting [2,3,1]
pg 11.34 is active+recovery_toofull+degraded, acting [2,3,1]发现osd的存储空间不够了,已经很明确了。接下来使用ceph df看一下具体哪个pool池不够用了
[root@ceph-01 ~]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 37 GiB 139 GiB 143 GiB 79.68
TOTAL 180 GiB 37 GiB 139 GiB 143 GiB 79.68
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
abcdocker 1 64 618 MiB 350 1.8 GiB 100.00 0 B
.rgw.root 2 32 1.2 KiB 4 768 KiB 100.00 0 B
default.rgw.control 3 32 0 B 8 0 B 0 0 B
default.rgw.meta 4 32 1.7 KiB 7 1.1 MiB 100.00 0 B
default.rgw.log 5 32 0 B 207 0 B 0 0 B
default.rgw.buckets.index 6 32 0 B 2 0 B 0 0 B
default.rgw.buckets.data 7 32 0 B 0 0 B 0 0 B
cephfs_data 8 64 10 GiB 2.56k 30 GiB 100.00 0 B
cephfs_metadata 9 64 825 KiB 23 3.9 MiB 100.00 0 B
kubernetes 11 128 36 GiB 9.41k 107 GiB 100.00 0 B
fs_data 12 8 158 B 1 192 KiB 100.00 0 B
fs_metadata 13 8 641 KiB 24 3.2 MiB 100.00 0 B
kube 14 128 0 B 0 0 B 0 0 B
abcdocker_rbd 15 32 196 MiB 67 592 MiB 100.00 0 B
abcdocker_data 16 128 0 B 0 0 B 0 0 B
cephfs-data 17 16 0 B 0 0 B 0 0 B
cephfs-metadata 18 16 0 B 0 0 B 0 0 B
i4t_data 19 16 168 B 2 384 KiB 100.00 0 B
i4t_metadata 20 16 196 KiB 25 2.3 MiB 100.00 0 B 先临时解决磁盘告警的问题,为手动删除之前创建的废弃rbd镜像
[root@ceph-01 ~]# rbd -p abcdocker ls
ceph-bak-new.img
ceph-bak.img
ceph-temp.img
ceph-test-01.img
ceph-test-02.img
ceph-test-03.img
ceph-trash.img
[root@ceph-01 ~]# rbd rm abcdocker/ceph-test-03.img
Removing image: 100% complete...done.
[root@ceph-01 ~]#
[root@ceph-01 ~]#
[root@ceph-01 ~]# rbd rm abcdocker/ceph-test-02.img
Removing image: 100% complete...done.清理完成后发现资源还是不够使用,接下来进行osd扩容
找到ceph-04服务器,关闭服务器进行扩容,添加一块100g的
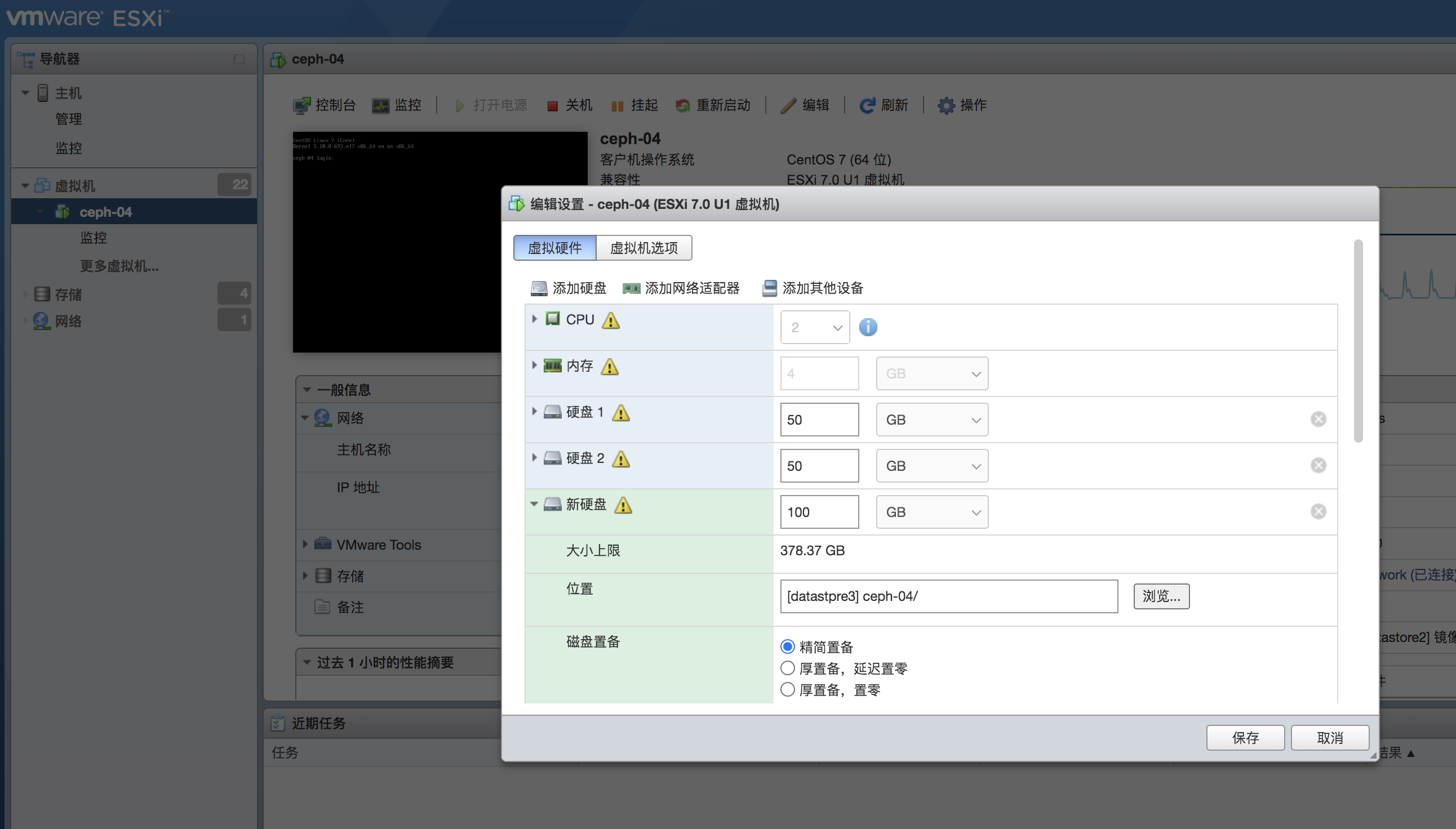
接下来开机进入服务器,先检查下硬盘是否挂载成功
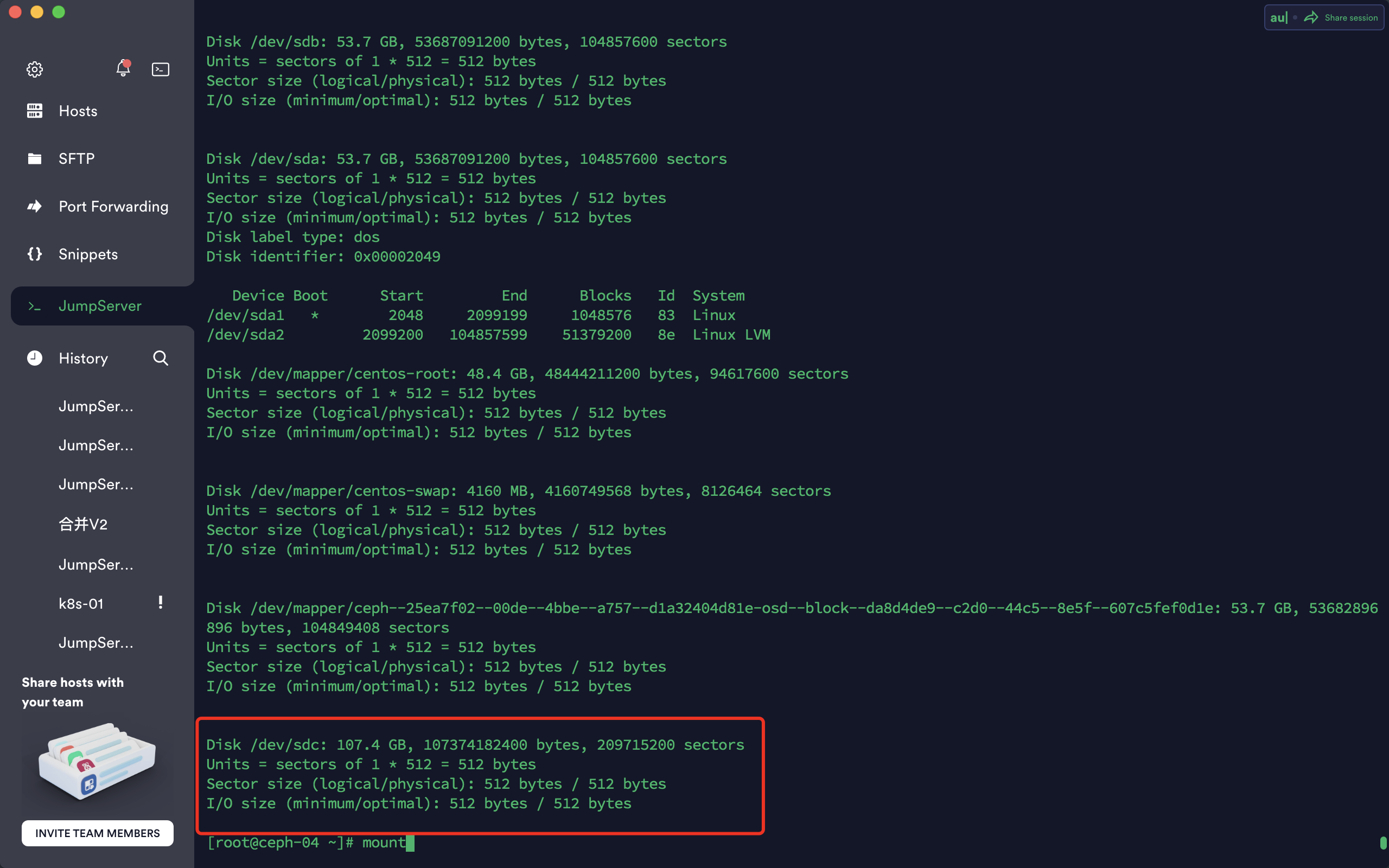
sdc为新增的100g硬盘
[root@ceph-04 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 49G 0 part ├─centos-root 253:0 0 45.1G 0 lvm / └─centos-swap 253:1 0 3.9G 0 lvm [SWAP] sdb 8:16 0 50G 0 disk └─ceph--25ea7f02--00de--4bbe--a757--d1a32404d81e-osd--block--da8d4de9--c2d0--44c5--8e5f--607c5fef0d1e 253:2 0 50G 0 lvm sdc 8:32 0 100G 0 disk sr0 11:0 1 1024M 0 rom [root@ceph-04 ~]#
通过fdisk -l 再次检查
接下来进入到ceph-01管理节点,为们需要在/root/ceph-deploy目录添加osd
#同步配置文件,同步配置文件需要进入到对应的目录,之前安装的ceph-deploy目录中
[root@ceph-01 ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-04
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy --overwrite-conf config push ceph-04
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : True
[ceph_deploy.cli][INFO ] subcommand : push
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x1bd3638>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] client : ['ceph-04']
[ceph_deploy.cli][INFO ] func : <function config at 0x1bafaa0>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.config][DEBUG ] Pushing config to ceph-04
root@ceph-04's password:
root@ceph-04's password:
[ceph-04][DEBUG ] connected to host: ceph-04
[ceph-04][DEBUG ] detect platform information from remote host
[ceph-04][DEBUG ] detect machine type
[ceph-04][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[root@ceph-01 ceph-deploy]# 接下来进行osd扩容命令
#ceph-04节点之前已经安装ceph了,我只扩容osd就可以.如果没有安装ceph还需要安装ceph节点
[root@ceph-01 ceph-deploy]# ceph-deploy osd create ceph-04 --data /dev/sdc扩容完成
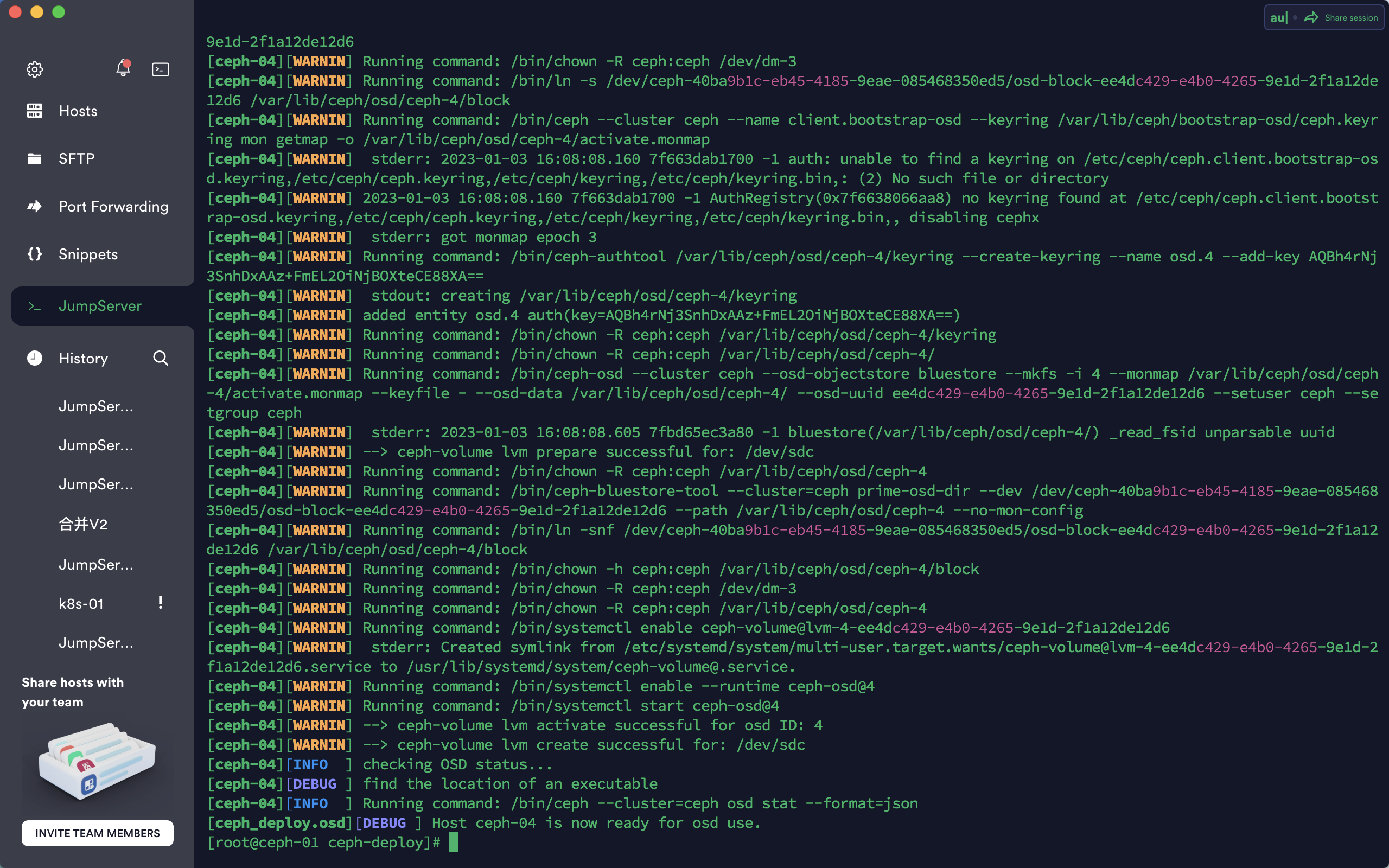
osd数据同步,需要稍等一会
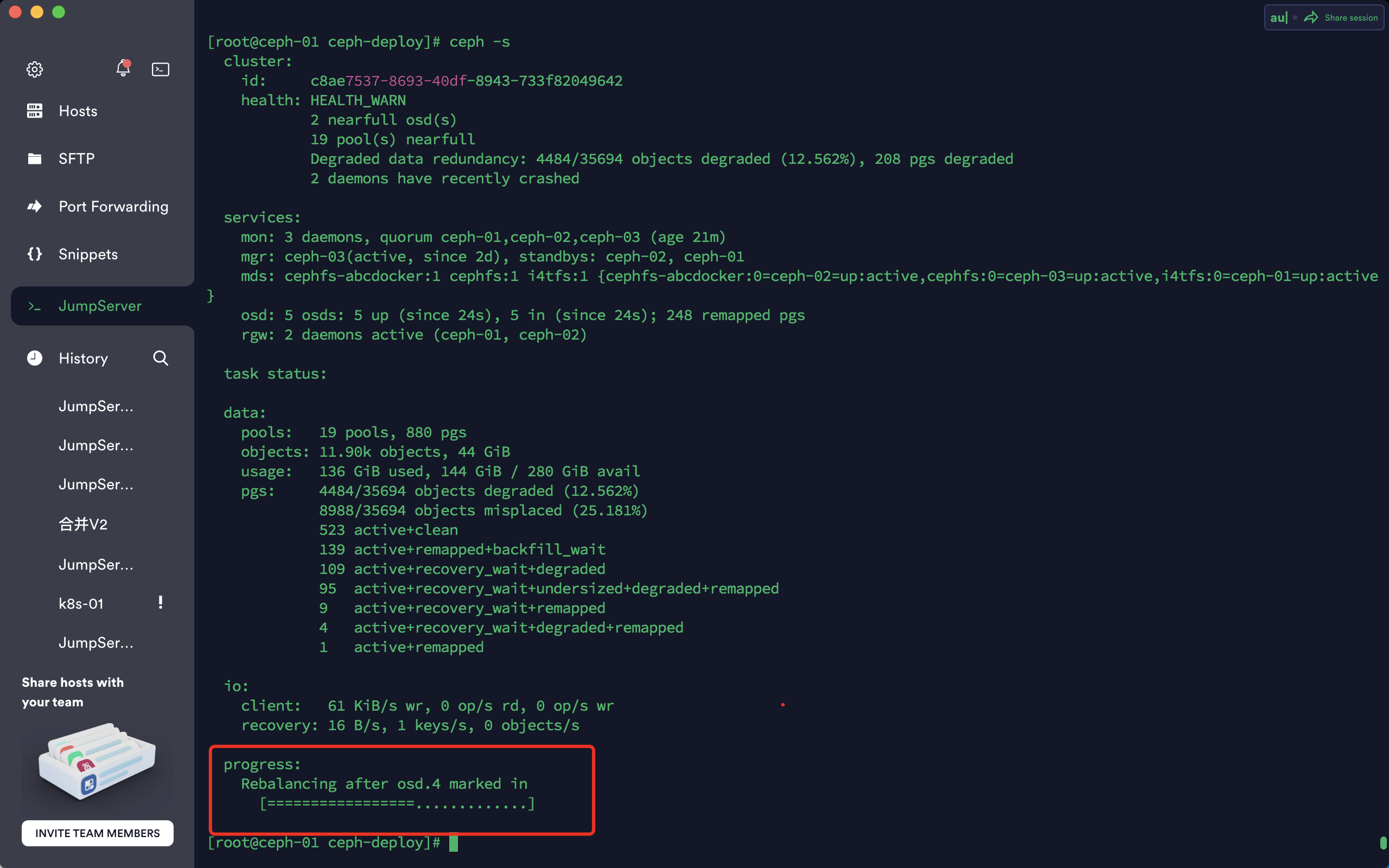
实际上此时osd已经添加成功
[root@ceph-01 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.27338 root default
-3 0.07809 host ceph-01
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000
-5 0.04880 host ceph-02
1 hdd 0.04880 osd.1 down 1.00000 1.00000
-7 0.04880 host ceph-03
2 hdd 0.04880 osd.2 up 1.00000 1.00000
-9 0.09769 host ceph-04
4 hdd 0.09769 osd.4 up 1.00000 1.00000 在ceph dashboard中也可以看到osd的详细信息
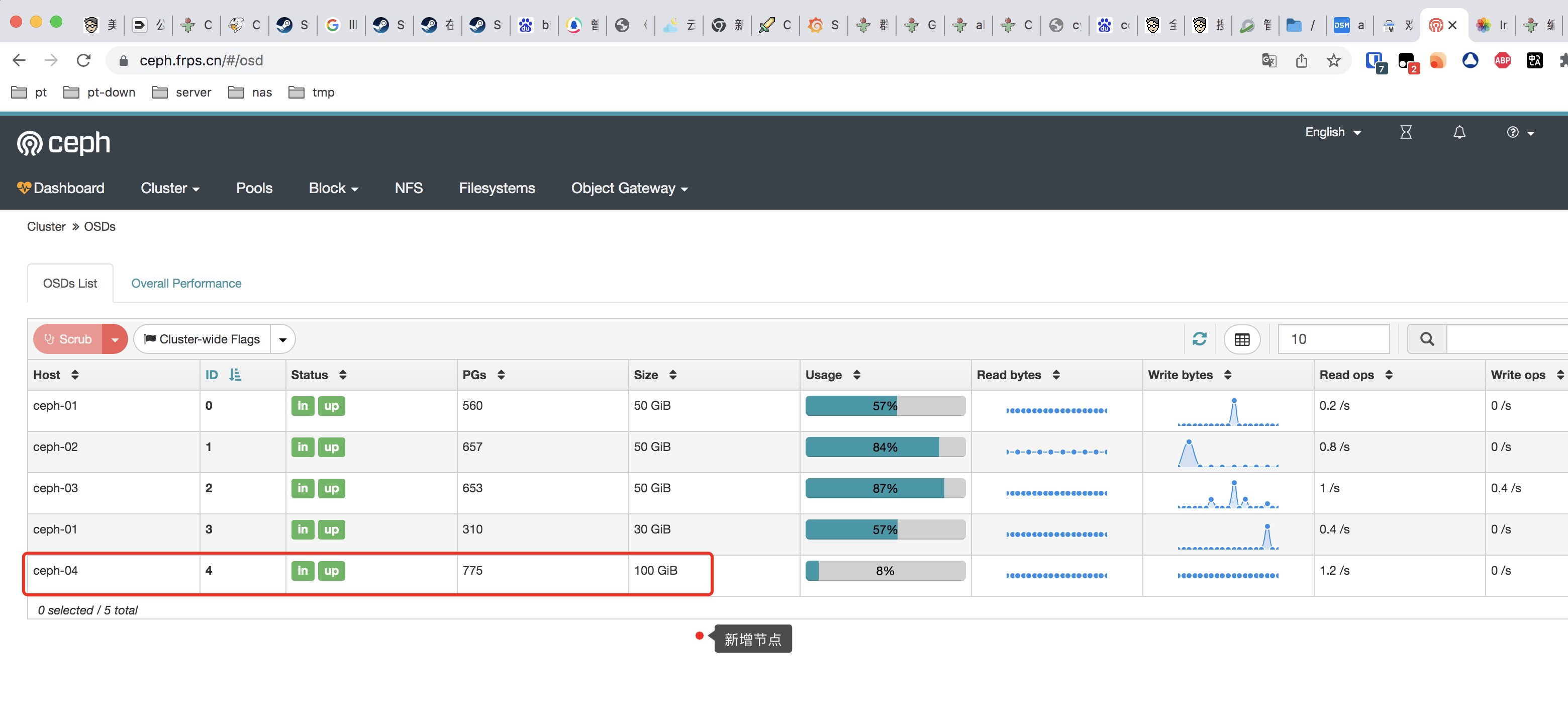
接下来就是等待pg crashed完毕