
针对于Kafka集群监控,目前有多种监控源Kafka Exporter以及Jmx Exporter。想要完整的监控Kafka最好的情况下是把这两个metric都添加进行监控
Kafka Exporter metric数据如下
| Metric | 作用 |
|---|---|
| kafka_topic_partitions | 该topic的分区数 |
| kafka_topic_partition_current_offset | topic当前偏移量 |
| kafka_topic_partition_oldest_offset | Broker的最旧偏移量 |
| kafka_topic_partition_in_sync_replica | topic同步副本数 |
| kafka_topic_partition_leader | Leader Broker ID |
| kafka_topic_partition_leader_is_preferred | topic正在使用首选代理 |
| kafka_topic_partition_replicas | topic的副本数 |
| kafka_topic_partition_under_replicated_partition | topic、分区处于复制状态 |
Jmx Exporter metric数据源如下
kafka_server_brokertopicmetrics_oneminuterate:Kafka服务的BrokerTopicMetrics一分钟速率(bytes/sec、messages/sec)kafka_server_brokertopicmetrics_meanrate:Kafka服务的BrokerTopicMetrics平均速率(bytes/sec、messages/sec)kafka_controller_kafkacontroller_value:Kafka控制器的离线分区计数和当前有效控制器计数kafka_server_replicafetchermanager_value:Kafka服务的ReplicaFetcherManager最大滞后值jmx_scrape_duration_seconds:JMX抓取数据所花费的时间jmx_scrape_error:JMX抓取消息失败的次数jvm_memory_bytes_used:JVM中使用的字节数(区域:堆、非堆)jvm_memory_bytes_committed:JVM中提交的字节数(区域:堆、非堆)jvm_memory_bytes_max:JVM中的最大使用空间(区域:堆、非堆)jvm_memory_bytes_init:JVM中的初始使用空间(区域:堆、非堆)jvm_memory_pool_bytes_used:JVM内存池使用的字节数(池:代码缓存、元空间、压缩类空间、eden空间、survivor空间、old gen)jvm_memory_pool_bytes_committed:JVM内存池已提交的字节数(池:代码缓存、元空间、压缩类空间、eden空间、survivor空间、old gen)jvm_memory_pool_bytes_max:JVM内存池的最大使用字节数(池:代码缓存、元空间、压缩类空间、eden空间、survivor空间、old gen)jvm_memory_pool_bytes_init:JVM内存池的初始字节数(池:代码缓存、元空间、压缩类空间、eden空间、survivor空间、old gen)jmx_config_reload_success_total:成功重新加载配置的次数jmx_config_reload_failure_total: 配置重新加载失败的次数。jvm_buffer_pool_used_bytes: 给定 JVM 缓冲池已使用的字节数。jvm_buffer_pool_capacity_bytes: 给定 JVM 缓冲池的字节容量。jvm_buffer_pool_used_buffers: 给定 JVM 缓冲池使用的缓冲区数量。jvm_info: JVM 版本信息。process_cpu_seconds_total: 用户和系统 CPU 时间的总计,在秒钟内度量。process_start_time_seconds: 进程的启动时间,从 Unix 纪元开始,以秒为单位量化。process_open_fds: 打开的文件描述符数量。process_max_fds: 最大打开的文件描述符数量。process_virtual_memory_bytes: 虚拟内存大小,以字节数表示。process_resident_memory_bytes: 常驻内存大小,以字节数表示。jvm_gc_collection_seconds_count: 给定 JVM 垃圾回收器的时间(秒)总计。jvm_threads_current: JVM 中当前线程数量。jvm_threads_daemon: JVM 中的守护线程数量。jvm_threads_peak: JVM 中线程峰值数量。jvm_threads_started_total: 启动的 JVM 线程数量。jvm_threads_deadlocked: 处于死锁状态、阻塞等待对象监控器或可拥有同步器的 JVM 线程数量。jvm_threads_deadlocked_monitor: 处于死锁状态、阻塞等待对象监控器的 JVM 线程数量。jvm_classes_loaded: JVM 中当前已加载的类数量。jvm_classes_loaded_total: 此指标计数器,代表自 JVM 启动以来已加载的类的总数。jvm_classes_unloaded_total: 此指标计数器,代表自 JVM 启动以来已卸载的类的总数。kafka_server_replicamanager_value: 表示对 Kafka 的复制管理器进行管理时所暴露的属性值。kafka_server_brokertopicmetrics_count: 表示 Kafka 游戏服务器的专家主题指标值。
JMX Exporter 安装
helm默认已经为我们配置jmx exporter模块,我们直接开启就可以
jmx:
## @param metrics.jmx.enabled Whether or not to expose JMX metrics to Prometheus
##
enabled: true #默认为false使用helm更新values.yaml文件
[root@k8s-02 kafka]# cd kafka
[root@k8s-02 kafka]# helm upgrade kafka -n kafka .当我们更新后,pod会重启。等待重启完毕后我们可以curl jmx的metric
[root@k8s-02 kafka]# kubectl get pod,svc -n kafka
NAME READY STATUS RESTARTS AGE
pod/kafka-0 2/2 Running 0 10h
pod/kafka-1 2/2 Running 0 10h
pod/kafka-2 2/2 Running 0 10h
pod/zookeeper-0 1/1 Running 0 19h
pod/zookeeper-1 1/1 Running 0 19h
pod/zookeeper-2 1/1 Running 0 19h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kafka ClusterIP 10.110.245.79 <none> 9092/TCP 19h
service/kafka-headless ClusterIP None <none> 9092/TCP,9094/TCP 19h
service/kafka-jmx-metrics ClusterIP 10.102.182.165 <none> 5556/TCP #jmx端口号 10h
service/zookeeper ClusterIP 10.99.142.88 <none> 2181/TCP,2888/TCP,3888/TCP 19h
service/zookeeper-headless ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 19hkafka-jmx-metrics为Kafka的metric
其实此时我们就可以修改Promethues监控,如果我们的监控是在集群内,就可以修改Promethues configmap,我这里Promethues是在集群外,所以我修改一下jmx svc模式使用nodeport的方式
[root@k8s-02 kafka]# kubectl edit svc -n kafka kafka-jmx-metrics
#修改下面配置
type: NodePort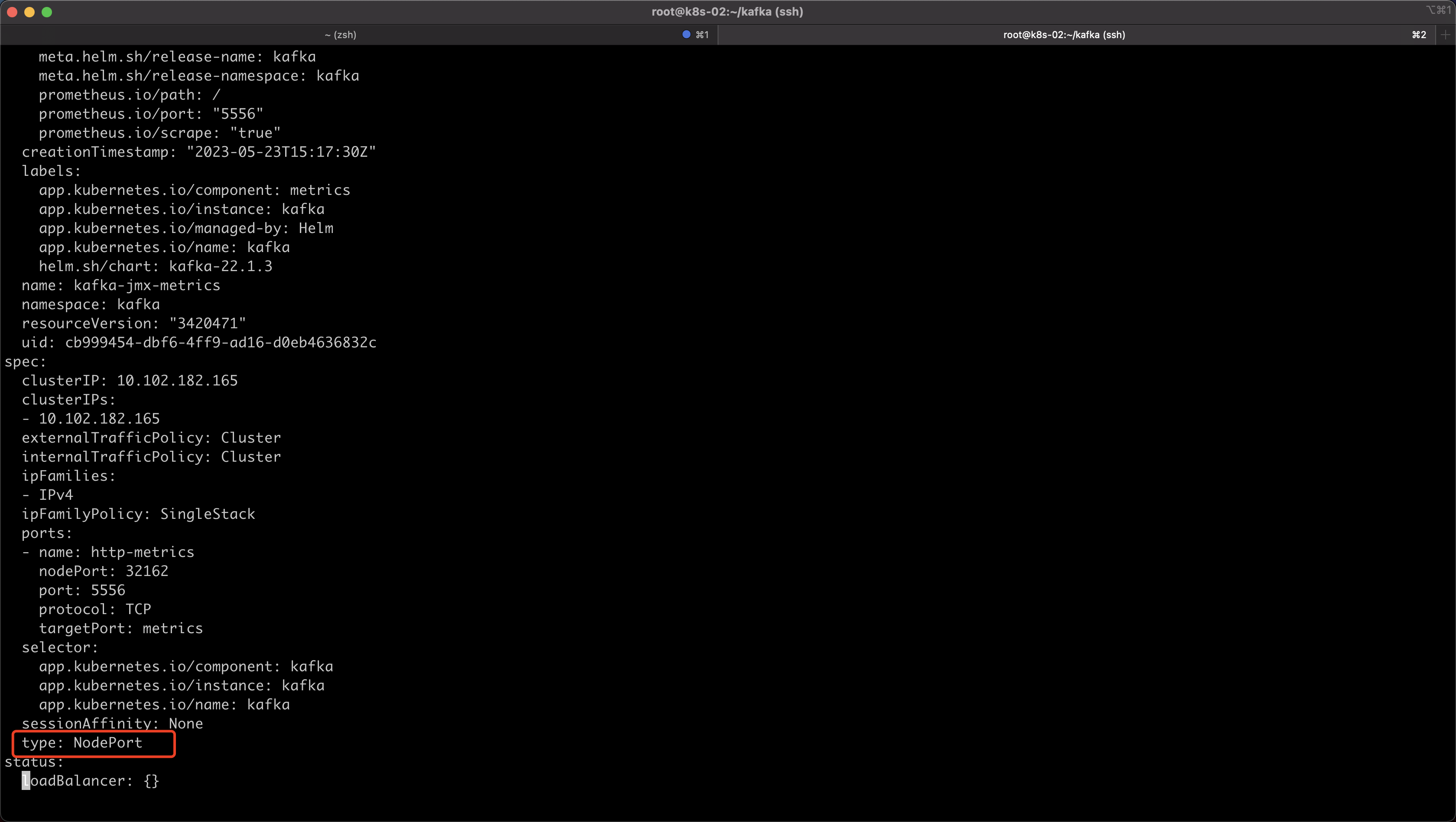
Kafka Exporter 安装
helm地址https://artifacthub.io/packages/helm/prometheus-community/prometheus-kafka-exporter
获取存储库信息
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update下载kafka_exporter包
[root@k8s-02 ~]# helm pull prometheus-community/prometheus-kafka-exporter解压,不同版本tag号也不相同,按需修改
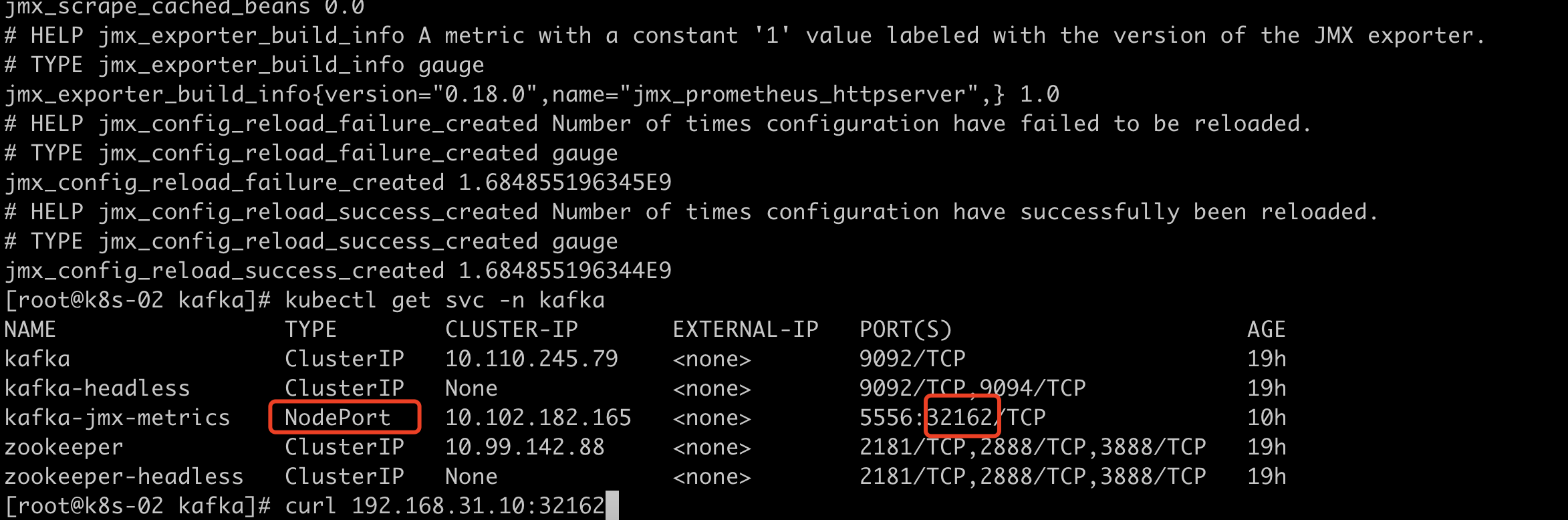
[root@k8s-02 ~]# tar xf prometheus-kafka-exporter-2.1.0.tgz 先确定Kafka svc地址
[root@k8s-02 prometheus-kafka-exporter]# kubectl get svc -n kafka
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kafka ClusterIP 10.110.245.79 <none> 9092/TCP 2d
kafka-headless ClusterIP None <none> 9092/TCP,9094/TCP 2d
kafka-jmx-metrics NodePort 10.102.182.165 <none> 5556:32162/TCP 39h
zookeeper ClusterIP 10.99.142.88 <none> 2181/TCP,2888/TCP,3888/TCP 2d
zookeeper-headless ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 2d
#我这里直接使用kafka-headless 地址编辑kafka_exporter配置文件
[root@k8s-02 ~]# cd prometheus-kafka-exporter
[root@k8s-02 prometheus-kafka-exporter]# vim values.yaml
kafkaServer:
- kafka-headless:9092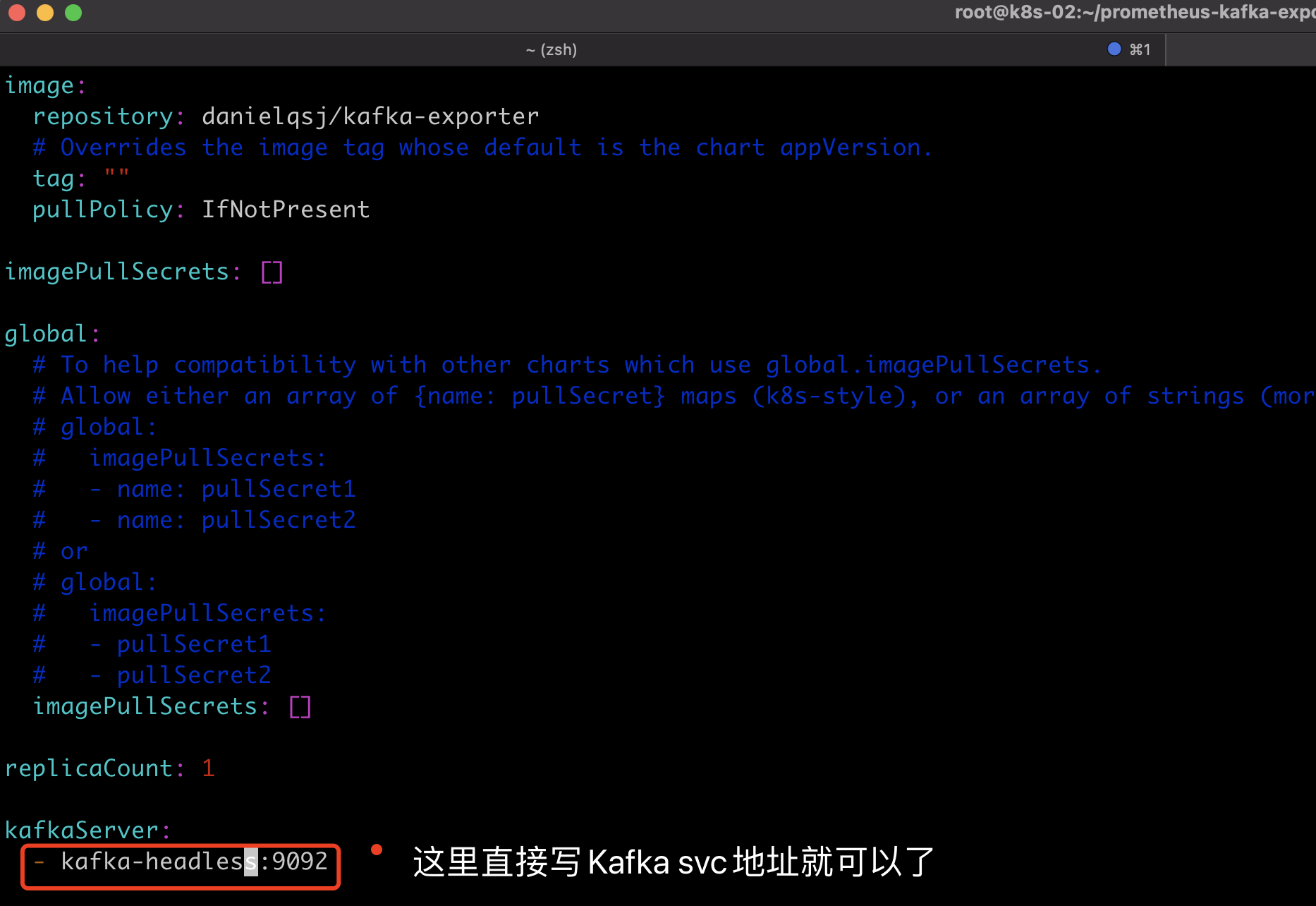
创建,这里我就将kafka_exporter放在kafka 命名空间中
[root@k8s-02 prometheus-kafka-exporter]# helm install prometheus-kafka-exporter -n kafka .
W0525 14:32:04.881290 24679 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0525 14:32:04.912874 24679 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: prometheus-kafka-exporter
LAST DEPLOYED: Thu May 25 14:32:04 2023
NAMESPACE: kafka
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace kafka -l "app=prometheus-kafka-exporter,release=prometheus-kafka-exporter" -o jsonpath="{.items[0].metadata.name}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl port-forward $POD_NAME 8080:80
[root@k8s-02 prometheus-kafka-exporter]#
[root@k8s-02 prometheus-kafka-exporter]#
[root@k8s-02 prometheus-kafka-exporter]# kubectl get pod -n kafka
NAME READY STATUS RESTARTS AGE
kafka-0 2/2 Running 0 28h
kafka-1 2/2 Running 0 28h
kafka-2 2/2 Running 0 28h
prometheus-kafka-exporter-7854896758-vxh95 1/1 Running 0 16s
zookeeper-0 1/1 Running 0 2d
zookeeper-1 1/1 Running 0 2d
zookeeper-2 1/1 Running 0 2d修改svc模式,由于我的Promethues在集群外,我这里手动修改一下nodeport方式 (也可以创建的时候在value.yaml中直接修改好)
[root@k8s-02 prometheus-kafka-exporter]# kubectl get svc -n kafka
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kafka ClusterIP 10.110.245.79 <none> 9092/TCP 2d
kafka-headless ClusterIP None <none> 9092/TCP,9094/TCP 2d
kafka-jmx-metrics NodePort 10.102.182.165 <none> 5556:32162/TCP 39h
prometheus-kafka-exporter ClusterIP 10.100.94.122 <none> 9308/TCP 44s
zookeeper ClusterIP 10.99.142.88 <none> 2181/TCP,2888/TCP,3888/TCP 2d
zookeeper-headless ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 2d
[root@k8s-02 prometheus-kafka-exporter]# kubectl edit svc prometheus-kafka-exporter -n kafka
type: NodePort #修改为NodePort修改完成我们访问nodeport测试
[root@k8s-02 prometheus-kafka-exporter]# kubectl get svc -n kafka
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kafka ClusterIP 10.110.245.79 <none> 9092/TCP 2d
kafka-headless ClusterIP None <none> 9092/TCP,9094/TCP 2d
kafka-jmx-metrics NodePort 10.102.182.165 <none> 5556:32162/TCP 39h
prometheus-kafka-exporter NodePort 10.100.94.122 <none> 9308:31444/TCP 2m15s
zookeeper ClusterIP 10.99.142.88 <none> 2181/TCP,2888/TCP,3888/TCP 2d
zookeeper-headless ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 2d
[root@k8s-02 prometheus-kafka-exporter]# curl 192.168.31.10:31444
<html>
<head><title>Kafka Exporter</title></head>
<body>
<h1>Kafka Exporter</h1>
<p><a href='/metrics'>Metrics</a></p>
</body>
</html>Promethues 集成Exporter
添加Promethues配置文件,将jmx_exporter和Kafka Export配置添加上
- kafka exporter
- jmx exporter
- job_name: 'kafka_exporter'
metrics_path: '/metrics'
static_configs:
- targets:
- 'i4t.com:30882'
labels:
env: "abcdocker"
- job_name: 'kafka_jmx_exporter'
metrics_path: '/metrics'
static_configs:
- targets:
- 'i4t.com:32162'
labels:
env: "abcdocker"- env 为了设置标识,后续区分不同环境
添加完后重启Promethues

Alertmanager 告警配置
[root@prometheus rules]# cat /etc/prometheus/rules/kafka_jmx_exporter.yaml
groups:
- name: Kafka 集群监控JMX & Kafka Exporter
rules:
- alert: "kafka集群脑裂"
expr: sum(kafka_controller_kafkacontroller_activecontrollercount_value{env="abcdocker"}) by (env) > 1
for: 0m
labels:
severity: warning
annotations:
description: '激活状态的控制器数量为{{$value}},集群可能出现脑裂'
summary: '{{$labels.env}} 集群出现脑裂,请检查集群之前的网络'
- alert: "kafka集群没有活跃的控制器"
expr: sum(kafka_controller_kafkacontroller_activecontrollercount_value{env="abcdocker"}) by (env) < 1
for: 0m
labels:
severity: warning
annotations:
description: '激活状态的控制器数量为{{$value}},没有活跃的控制器'
summary: '{{$labels.env}} 集群没有活跃的控制器,集群可能无法正常管理'
- alert: "kafka节点异常"
expr: count(kafka_server_replicamanager_total_leadercount_value{env="abcdocker"}) by (env) < 3
for: 0m
labels:
severity: warning
annotations:
description: '{{$labels.env}} 集群的节点挂了,当前可用节点:{{$value}}'
summary: '{{$labels.env}} 集群的节点挂了'
- alert: "kafka集群出现leader不在首选副本上的分区"
expr: sum(kafka_controller_kafkacontroller_preferredreplicaimbalancecount_value{env="abcdocker"}) by (env) > 0
for: 1m
labels:
severity: warning
annotations:
description: '{{$labels.env}} 集群出现leader不在首选副本上的分区,数量:{{$value}}'
summary: '{{$labels.env}} 集群出现leader不在首选副本上的分区,分区副本负载不均衡,考虑使用kafka-preferred-replica-election脚本校正'
- alert: "kafka集群离线分区数量大于0"
expr: sum(kafka_controller_kafkacontroller_offlinepartitionscount_value{env="abcdocker"}) by (env) > 0
for: 0m
labels:
severity: warning
annotations:
description: '{{$labels.env}} 集群离线分区数量大于0,数量:{{$value}}'
summary: '{{$labels.env}} 集群离线分区数量大于0'
- alert: "kafka集群未保持同步的分区数大于0"
expr: sum(kafka_server_replicamanager_total_underreplicatedpartitions_value{env="abcdocker"}) by (env) > 0
for: 0m
labels:
severity: warning
annotations:
description: '{{$labels.env}} 集群未保持同步的分区数大于0,数量:{{$value}}'
summary: '{{$labels.env}} 集群未保持同步的分区数大于0,可能丢失消息'
- alert: "kafka节点所在主机的CPU使用率过高"
expr: irate(process_cpu_seconds_total{env="abcdocker"}[5m])*100 > 50
for: 10s
labels:
severity: warning
annotations:
description: '{{$labels.env}} 集群CPU使用率过高,主机:{{$labels.instance}},当前CPU使用率:{{$value}}'
summary: '{{$labels.env}} 集群CPU使用率过高'
- alert: "kafka集群消息积压告警"
expr: sum(consumer_lag{env="abcdocker"}) by (groupId, topic, env) > 20000
for: 30s
labels:
severity: warning
annotations:
description: '{{$labels.env}} 集群出现消息积压,消费组:{{$labels.groupId}},topic:{{$labels.topic}},当前积压值:{{$value}}'
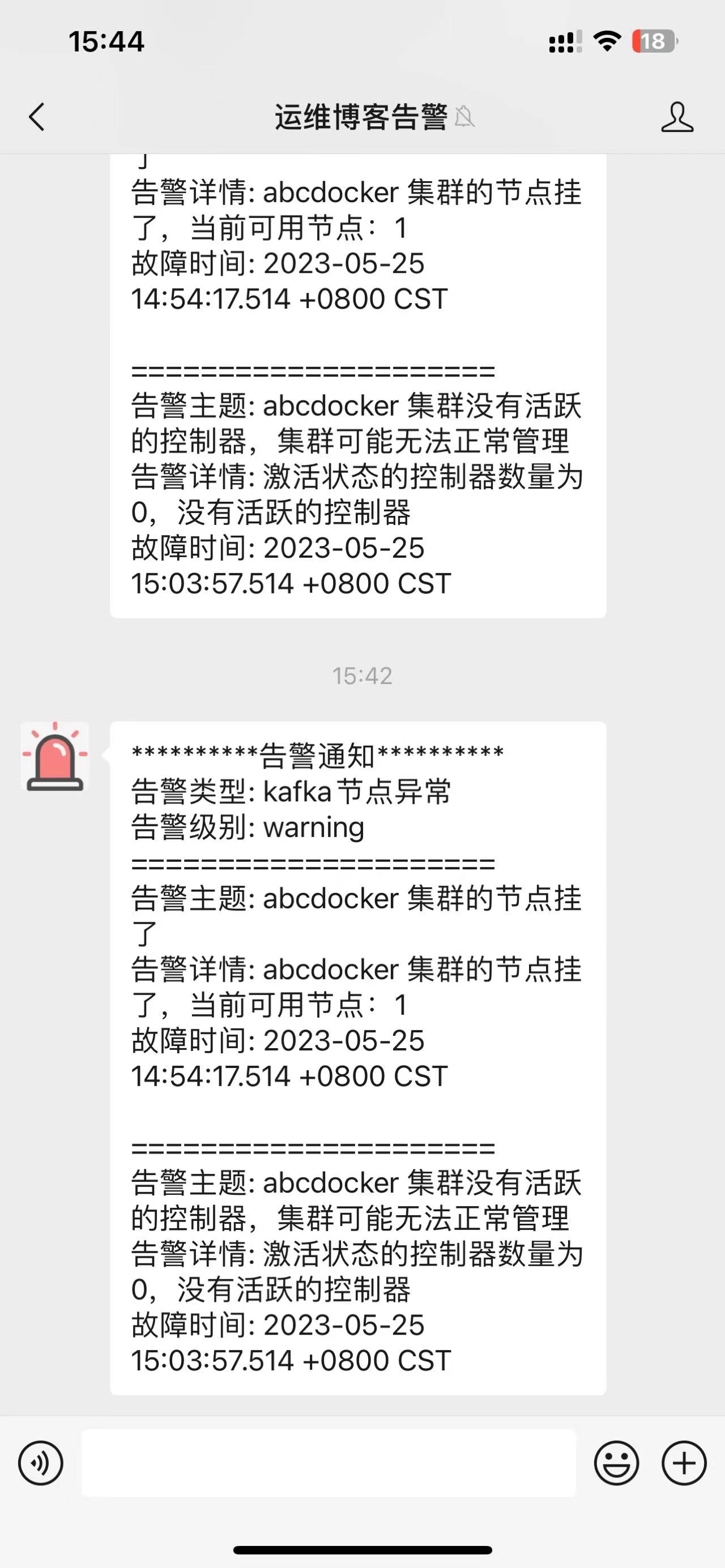
summary: '{{$labels.env}} 集群出现消息积压'重启Promethues后,我们在Alert就可以看到告警信息
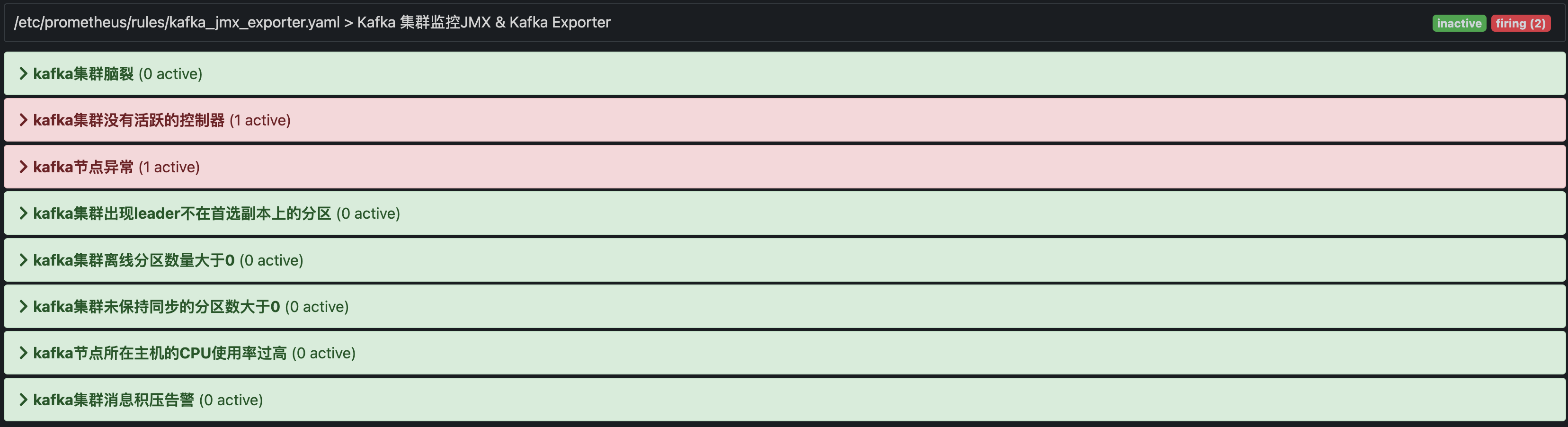
我这里已经触发告警,我们在微信就可以看到相关的告警信息
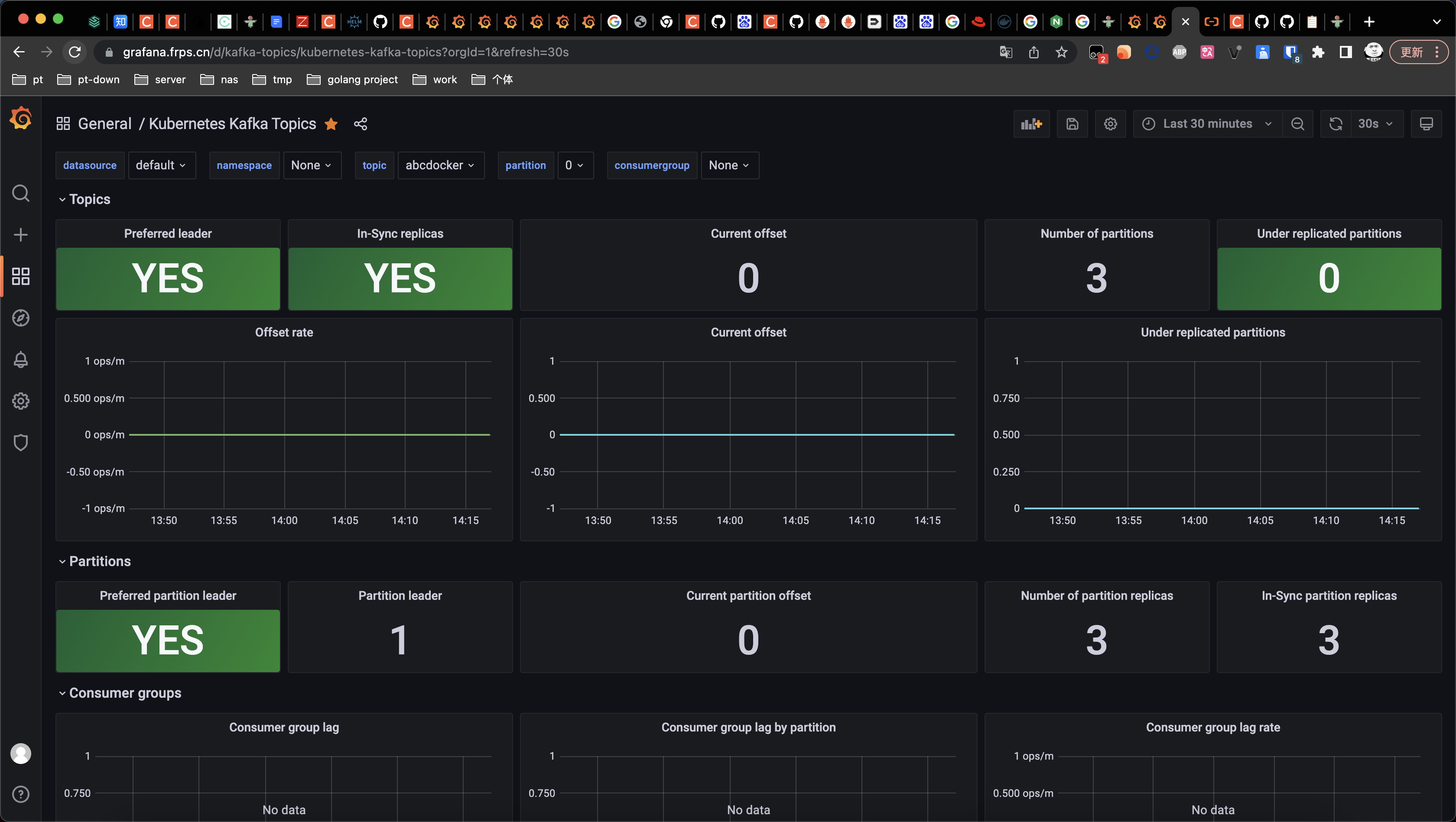
Grafana 监控图表
https://grafana.com/grafana/dashboards/10122-kafka-topics/
导入ID10122


[…] 可以看下面的文章 https://i4t.cn/13732.html […]